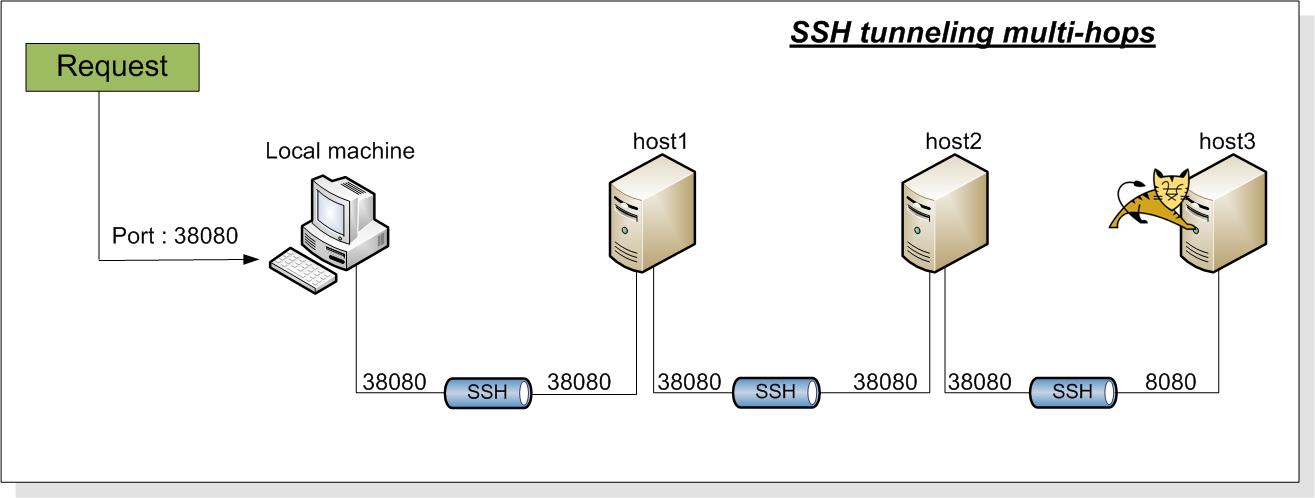
3. Glassfish cluster configuration
With our pre-requirements covered it's time to start configuring our cluster
A. Enabling remote access on the glassfish servers
By default the remote administration feature is disabled on the GlassFishServer
This is to reduce your exposure to an attack from elsewhere in the network.
So if you attempt to administer the server remotely you will get a 403 - Forbidden HTTP status
as the response. This is true regardless of whether you use the asadmin command, an IDE, or the REST interface.
You will need to start up the glassfish server on each one of your servers by executing the following command
$GFISH_HOME/bin/asadmin start-domain domain1
Once the servers are up you can turn remote administration on running the following command locally in each one of the servers (please ensure the glassfish instance is
running when you execute the command) and when prompted enter the appropriate user/password :
$GFISH_HOME/bin/asadmin enable-secure-admin
This commands actually accomplishes 2 things it enables remote administration and encrypts all admin traffic.
In order for your modifications to be taken into account you will need to restart the glassfish server by running the following commands :
$GFISH_HOME/bin/asadmin stop-domain domain1
Once the sever is stopped you need to start it again so it can pick-up the remote admin parameter
You can now stop the running servers on all the nodes (except server1) by executing the above stop-domaincommand
Note : From this point forward all the operations should be executed on the server hosting the DAS(Domain Admin Server)
in our case server1 so make sure it's running.
Tip : To avoid having to type your glassfish user/password when you run each command you can check my other post regarding the asadmin login
command here
that will prompt you once your your credentials and store them in an encrypted file under /home/gfish/.asadminpass
B. Creating the cluster nodes
A node represents a host on which the GlassFish Server software is installed.
A node must exist for every host on which GlassFish Server instances reside. A node's configuration contains information
about the host such as the name of the host and the location where the GlassFish Server is installed on the host. For more info regarding glassfish nodes click
here
The node for server1 is automatically created when you create your domain so we will create a node for each of the remaining servers (server2 & server3).
Creating the node2 on server2
[server1]$ $GFISH_HOME/bin/asadmin create-node-ssh --nodehost=server2 node2
Enter admin user name> admin
Enter admin password for user "admin">
Command create-node-ssh executed successfully.
Creating the node3 on server3
[server1] $GFISH_HOME/bin/asadmin create-node-ssh --nodehost=server3 node3
Enter admin user name> admin
Enter admin password for user "admin">
Command create-node-ssh executed successfully.
Note : If you followed my tip regarding the credentials storage your output might be slightly different (no user/password prompt)
C. Creating the cluster
Once the nodes created it's time for us to create our cluster
[server1]$ $GFISH_HOME/bin/asadmin create-cluster myCluster
Enter admin user name> admin
Enter admin password for user "admin">
Command create-cluster executed successfully.
D. Creating the cluster instances
Now that we have the nodes and the cluster configured, we need to create the instances that will be part of the cluster.
a. Creating the local instance (instance that will be running on the same server as the DAS)
[server1]$ $GFISH_HOME/bin/asadmin create-local-instance --cluster myCluster --node localhost i_1
Command _create-instance-filesystem executed successfully.
Port Assignments for server instance i_1:
JMX_SYSTEM_CONNECTOR_PORT=28686
JMS_PROVIDER_PORT=27676
HTTP_LISTENER_PORT=28081
ASADMIN_LISTENER_PORT=24848
JAVA_DEBUGGER_PORT=29009
IIOP_SSL_LISTENER_PORT=23820
IIOP_LISTENER_PORT=23700
OSGI_SHELL_TELNET_PORT=26666
HTTP_SSL_LISTENER_PORT=28181
IIOP_SSL_MUTUALAUTH_PORT=23920
The instance, i_1, was created on host localhost
Command create-instance executed successfully.
b. Creating the remote instances
node2 --> i_2
[server1]$GFISH_HOME/bin/asadmin create-instance --cluster myCluster --node node2 i_2
node3 --> i_3
[server1]$GFISH_HOME/bin/asadmin create-instance --cluster myCluster --node node3 i_3
The message output should be similar to the one shown in the first code snippet (omitted for readability).
E. Working with the cluster
This section show a few useful commands when managing clusters
a. Showing clusters status
[server1]$GFISH_HOME/bin/asadmin list-clusters
myCluster running
b. Instance status
[server1]$ $GFISH_HOME/bin/asadmin list-instances
i_1 running
i_2 running
i_3 running
Command list-instances executed successfully.
c. Starting the cluster
/data/glassfish/bin/asadmin start-cluster myCluster
d. Stopping the cluster
$GFISH_HOME/bin/asadmin stop-cluster myCluster
d. Starting an instance
$GFISH_HOME/bin/asadmin start-instance i_1
d. Stopping an instance
$GFISH_HOME/bin/asadmin stop-instance i_1
e. Deploying a war to the cluster
$GFISH_HOME/bin/asadmin deploy --enabled=true --name=myApp:1.0 --target myCluster myApp.war
4. Configuring the glassfish as a daemon/service
In a production environment you will probably want your cluster to startup automatically (as a daemon/service) when your operating system boots
In this section I will show you how to create 2 possible scripts for starting/stopping a glassfish server under a
Linux CentOS distribution (please note that depending on your Linux distribution this might not be the same)
In our cluster configuration there are mainly 2 types of instances :
- DAS(Domain Admin Server) instance : This is our main instance it will handle the cluster configuration and propagate it to the cluster instances
- Clustered instance : A clustered instance inherits its configuration from the cluster to which the instance belongs and shares its configuration with other instances in the cluster.
Please note that due to this difference the startup scripts for each instance type will be slightly different.
Whether we are configuring a clustered instance or DAS instance the script will be under :
/etc/init.d/glassfish
A. Creating the service script for the DAS (server1)
The following is an example start-up script for managing a glassfish DAS instance.
It assumes the glassfish password is already stored in the .asadminpass file as show before.
#!/bin/bash
#
# chkconfig: 3 80 05
# description: Startup script for Glassfish
GLASSFISH_HOME=/opt/glassfish/bin;
GLASSFISH_OWNER=gfish;
GLASSFISH_DOMAIN=gfish;
CLUSTER_NAME=mycluster
export GLASSFISH_HOME GLASSFISH_OWNER GLASSFISH_DOMAIN CLUSTER_NAME
start() {
echo -n "Starting Glassfish: "
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin start-domain $GLASSFISH_DOMAIN"
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin start-cluster $CLUSTER_NAME"
echo "done"
}
stop() {
echo -n "Stopping Glassfish: "
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin stop-cluster $CLUSTER_NAME"
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin stop-domain $GLASSFISH_DOMAIN"
echo "done"
}
stop_cluster(){
echo -n "Stopping glassfish cluster $CLUSTER_NAME"
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin stop-cluster $CLUSTER_NAME"
echo "glassfish cluster stopped"
}
start_cluster(){
echo -n "Starting glassfish cluster $CLUSTER_NAME"
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin start-cluster $CLUSTER_NAME"
echo "Glassfish cluster started"
}
case "$1" in
start)
start
;;
stop)
stop
;;
stop-cluster)
stop_cluster
;;
start-cluster)
start_cluster
;;
restart)
stop
start
;;
*)
echo $"Usage: Glassfish {start|stop|restart|start-cluster|stop-cluster}"
exit
esac
B. Creating the service script for the cluster instances (server2,server3)
Below is an exemple script for configuring a glassfish cluster instance
#!/bin/bash
#
# chkconfig: 3 80 05
# description: Startup script for Glassfish
GLASSFISH_HOME=/opt/glassfish/bin;
GLASSFISH_OWNER=gfish;
NODE=n2
INSTANCE=i2
export GLASSFISH_HOME GLASSFISH_OWNER NODE INSTANCE
start() {
echo -n "Starting Glassfish: "
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin --user $GLASSFISH_ADMIN --passwordfile $GLASSFISH_PASSWORD start-local-instance --node $NODE --sync normal $INSTANCE"
echo "done"
}
stop() {
echo -n "Stopping Glassfish: "
su $GLASSFISH_OWNER -c "$GLASSFISH_HOME/asadmin stop-local-instance --node $NODE $INSTANCE"
echo "done"
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
*)
echo $"Usage: Glassfish {start|stop|restart}"
exit
esac
Warning : Since clustered instances cannot exist outside a cluster it's important that the local glassfish server is not started using
the asadmin start-domain.If you do so you will probably loose all your cluster configuration for that instance.
You should always start the clustered instances with the command shown above
7. Troubleshooting & additional resources
I'm getting the message 'remote failure ...'
remote failure: Warning: some parameters appear to be invalid.
SSH node not created. To force creation of the node with these parameters rerun the command using the --force option.
Could not connect to host arte-epg-api1.sdv.fr using SSH.
The subsystem request failed.
The server denied the request.
Command create-node-ssh failed.
This is probably because the SFTP subsystem is not enabled on the target node. Please ensure that the following line is uncommented in the sshd_config file
Subsystem sftp /usr/libexec/openssh/sftp-server
Where can I find the glassfish startup/shutdown scripts ?
You can find these scripts over at my github account